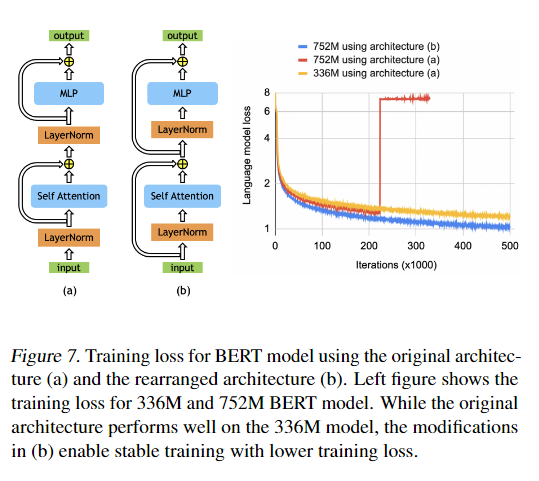
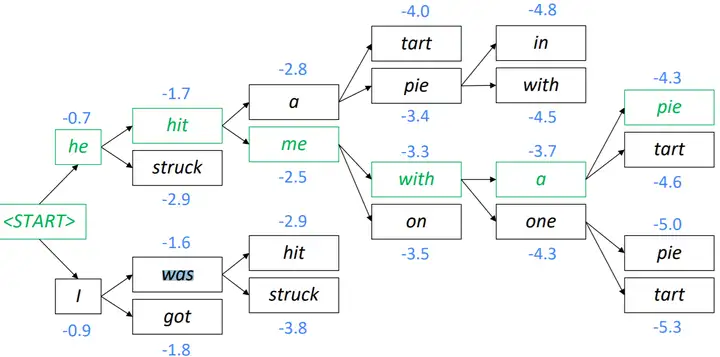
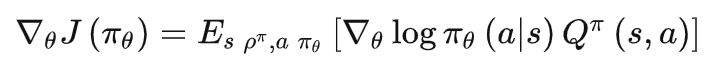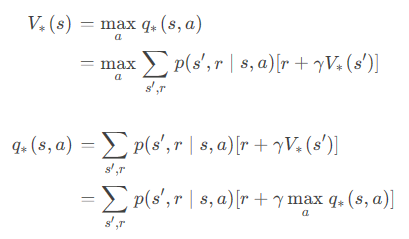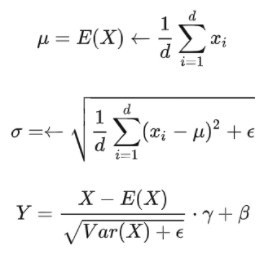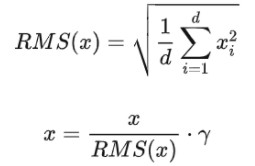大规模训练技术挑战
数据并行:每张卡部分数据
模型并行:将模型每一层是现成可以并行到多卡实现的形式,进而将单层的计算可以切分到多卡上
流水并行:对模型块切分,将不同的层放到不同的卡上
挑战:
模型比较大,单卡无法承载模型,需要用模型并行以及流水并行才能训练模型,但是会降低CPU的运算强度
大数据+大模型->巨大计算量。但由于显存墙的缘故,单卡运算强度低,多卡加速比较差->再多资源也可能无法训练完
显存挑战
模型训练对显存的占用可以分为两部分:一部分是模型 forward 时保存下来的临时变量,这部分显存会在反向传播时会逐渐释放掉,这部分一般被称为 Activations。另一部分则是参数、梯度等状态信息占用的显存,这部分一般被称为 Model States。
- 前向计算的过程是最占用显存的,降低这部分的峰值就能够给不超过显存墙
- 短板效应-Model states 和 Activations 都有可能造成显存墙问题。它们相互独立但又相互制约。任意一侧的增大都会导致留给另一侧的显存空间变小,所以单单对一侧做优化是不够的,必须同时优化 Model states 和 Activations。
- Transformer的大矩阵乘法能够拆分做模型并行,可以降低Activations的占用。
通信挑战
需要将切分的训练信息做聚合,问题:
- 更新频繁,但传输速率远比不上加速芯片的运算速率;
- 机器规模较大的时候,基于 Ring-AllReduce 的通信聚合方式所构造的 Ring 将越来越大(节点越多通信量越大、延迟越高),延迟将不可接受。
- 需要通信的梯度较多,带宽扛不住;多种并行也增加了通信的压力
- 大部分采用同步的通信步调,导致短板效应明显,单卡波动以及通信延迟导致问题变得更加严重
- 直接增大宽带-无法解决
受限于网络协议,宽带的利用率不够高;
计算挑战
需要较大的算力,但各种技术也会降低计算资源的利用率,需要考虑怎样提高计算效率
算子级别优化,需要解决的问题:
小算子过多,Kernel实现不够高效,内存局部性差
计算图优化,加速大规模训练,需要解决:
如何搜索出计算效率更高的计算图,如何用计算编译技术解决小算子问题,如何进行通信和计算的overlap 等
训练阶段系统设计-实现一个计算效率最高的系统设计
- 优秀分布式训练架构-扩展性强、节点很多也能保持较高加速比
- 平衡显存优化和速度优化
References
- 大规模训练系列之技术挑战
微调经验与技术说明
经验方法
- Freeze方法
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。
- P-Tuning方法

一种针对于大模型的soft-prompt方法。
P-Tuning,仅对大模型的Embedding加入新的参数。
P-Tuning-V2,将大模型的Embedding和每一层前都加上新的参数。
- lora方法
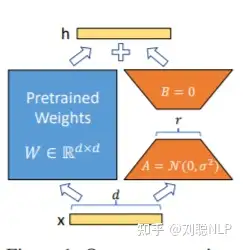
在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练额外增加的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量很小,达到仅训练很小的参数,就能获取较好的结果。
技术分类说明
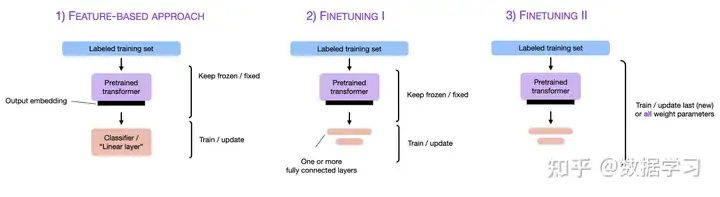
fine-tuning技术
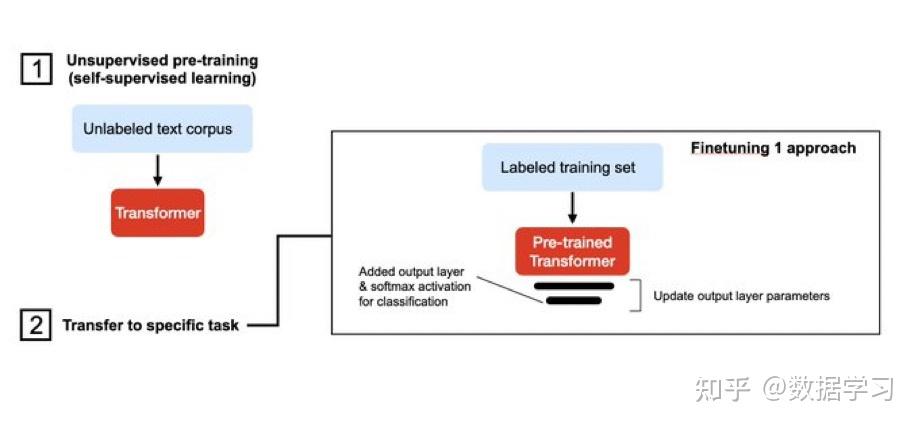
- parameter-efficient fine-tuning技术(PEFT)
旨在在尽可能减少所需的参数和计算资源的情况下,实现对预训练语言模型的有效微调。
- 蒸馏:学生模型(小模型)模仿教师模型(大模型)
- 适配器训练(adapter training):适配器是添加到预训练模型中的小型神经网络,用于特定任务的微调。这些适配器只占原始模型大小的一小部分,这使得训练更快,内存需求更低。适配器可以针对多种任务进行训练,然后插入到预训练模型中以执行新任务。eg:lora
- 渐进收缩(progressive shrinking):FT期间逐渐减小预训练模型,减少模型参数量的同时保证模型的性能。
- prompt-tuning技术
重点是调整输入提示(input prompt)而非修改模型参数,即不会对原有的参数做任何修改,只有输入提示被修改以适应下游的任务。
相比于FT优势:
- 计算成本和资源、时间等更少
- 更加灵活
相关技术:
Prefix tuning(前缀调整)
对特定任务学习连续提示,通过优化这个提示表示特征,模型能够在不修改底层模型的前提下实现不同的任务。
P-Tuning
不同在于这个对位置没有特定的要求
P-Tuning涉及训练可学习的称为“提示记号”的参数,这些参数与输入序列连接。这些提示记号是特定于任务的,在精调过程中进行优化,使得模型可以在保持原始模型参数不变的情况下在新任务上表现良好。
References
- 大模型LLM-微调经验分享&总结
- 预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning和prompt-tuning的介绍和对比
LoRA技术介绍
研究背景
在LoRA方法提出之前,也有很多方法尝试解决大模型微调困境的方法。其中有两个主要的方向:
(1) 添加adapter层;
(2) 由某种形式的输入层激活。
但是这两种方法都有局限性:
Adapter层会引入推理时延
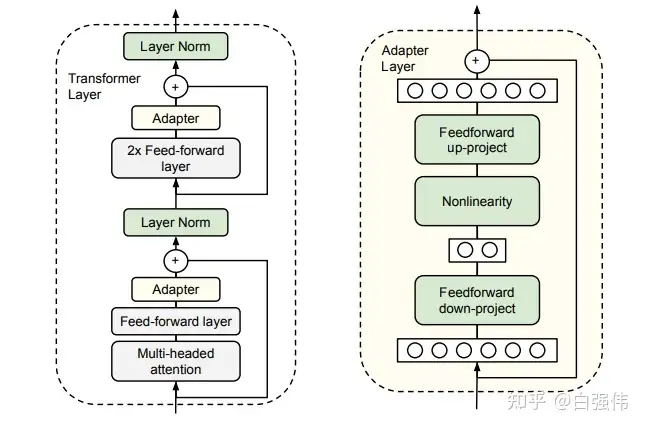
prefix-tuning难以优化

prefix-tuning方法是受语言模型in-context learning能力的启发,只要有合适的上下文则语言模型可以很好的解决自然语言任务。但是,针对特定的任务找到离散token的前缀需要花费很长时间,prefix-tuning提出使用连续的virtual token embedding来替换离散token。
技术细节
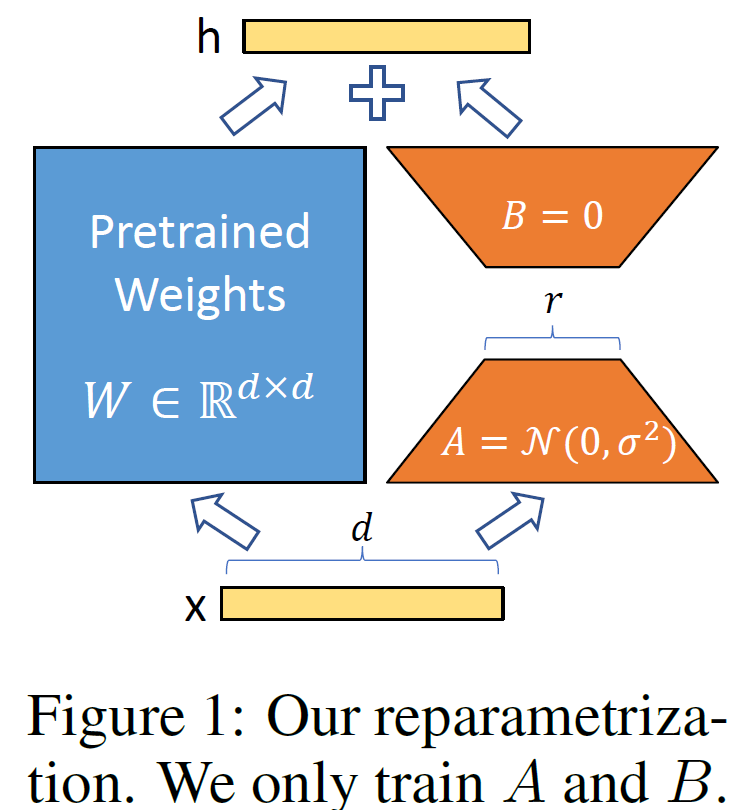
总体概括:LoRA的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型微调类似的效果。
其中,增加的是低秩分解矩阵,参数量小,也不会增加推理延迟。在实现过程中,会将该矩阵注入到transformer的每一层。
实现说明:
通常,神经网络中会包含许多进行矩阵乘法的稠密层,这些层通常是满秩的。相关研究表示其实预训练语言模型具有低的“内在维度”,受该工作的启发,在模型适配下游任务的过程中,权重更新也应该具有低的“内在秩”。
优点:显存和存储空间的减少。可以在部署时以更低的成本切换任务,仅需要交换LoRA权重即可。
References
- 【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
- LoRA(Low-Rank Adaptation of Large Language Models)– 一种大模型prompt-tuning调优方法
- LoRA:大语言模型参数高效性微调方法
- 深入浅出 LoRA - 知乎 (zhihu.com)
Chain of Thought
思维链主要用于提升模型的逻辑推理能力,使得AI能够有类似于人一样的推理能力。
研究背景
最早的相关工作是few-shot,one-shot,zero-shot等在推理时能够提供不同量的样本,使得模型的推理能力能够有进一步的提升。但这种方法依旧存在较大的问题,如果你的问题相对简单,不需要什么逻辑推理,可能靠大模型背答案就能做得不错,但是对于一些需要推理的问题,都不用太难,就一些简单的算术应用题,大模型就大概率不太 work。
相关工作

简单来说就是将原本的问题,经过多个中间步骤最终获取答案,实现更好的推理。
具体实现效果:常识推理能力赶超人类;数学逻辑推理能力大幅度提升;LLM可解释性更强。
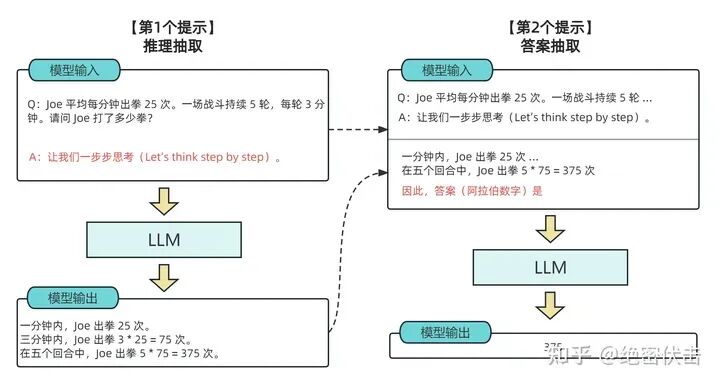
零样本思维链通过引入与样本无关指示,来实现自我增强
- 多数投票提高CoT性能——自洽性(Self-consistency)
其实核心就是对生成的多个结果选择取多数的答案,这一个可以直接通过控制temprature和Top-K来实现,很显然这会使得时间会变长。
- LtM(Least to Most prompting)
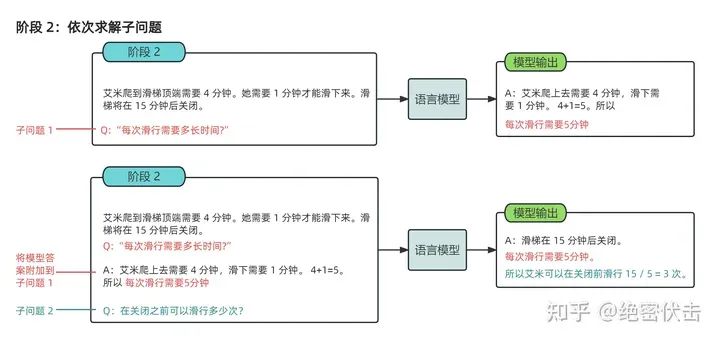
将问题按步骤拆分成多个子问题,解决完多个子问题后回答最终问题。具体训练就是分为多个CoT阶段实现。
- Flan-PaLM/T5:CoT + Finetuning
Flan-T5:在超大规模的任务上对模型进行微调,使得单个模型在1800多个NLP任务上都能够有很好的表现。
微调方法就是在加入CoT数据。其核心是对多任务数据的统一。
实现流程:
- 收集带有标签的数据,将每个任务定义为<数据,任务类型>
- 对数据的形式进行改写,比如改写成CoT的形式;并对是否需要CoT和few-shot,进行组合构造
- 训练过程:恒定的学习率以及 Adafactor 优化器;同时将多个训练样本打包成一个训练样本,通过特殊结束token进行分割。
结论:
- 微调有效果,模型越大越好,任务越多越好
- 混杂CoT很重要
旨在利用大模型思维链推理能力指导小模型解决复杂问题。
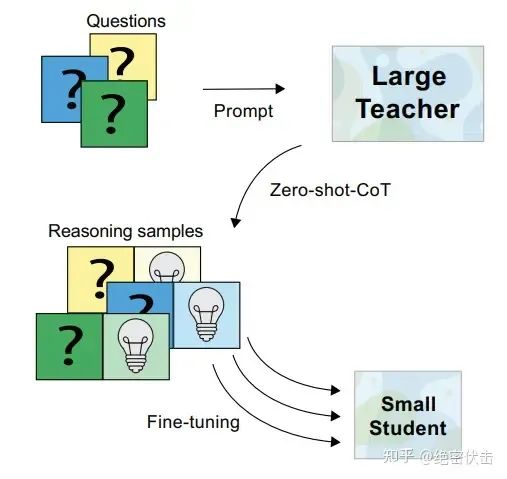
简单的说就是用ChatGPT这类大模型生成CoT数据,然后再喂给小模型进行微调。同时该方法需要生成尽可能多的数据。
CoT的局限性
- 思维链只有在模型规模足够大的时候才适用,如何实现小模型的思维链应用是值得探索的方向
- 应用领域有限,当前的实验结果只是在部分领域有所评估。另外,思维链只是提高模型的推理能力,但不代表模型真正理解内在的逻辑。
References
- 【他山之石】大模型思维链(Chain-of-Thought)技术原理
LLM-Tricks
数据相关
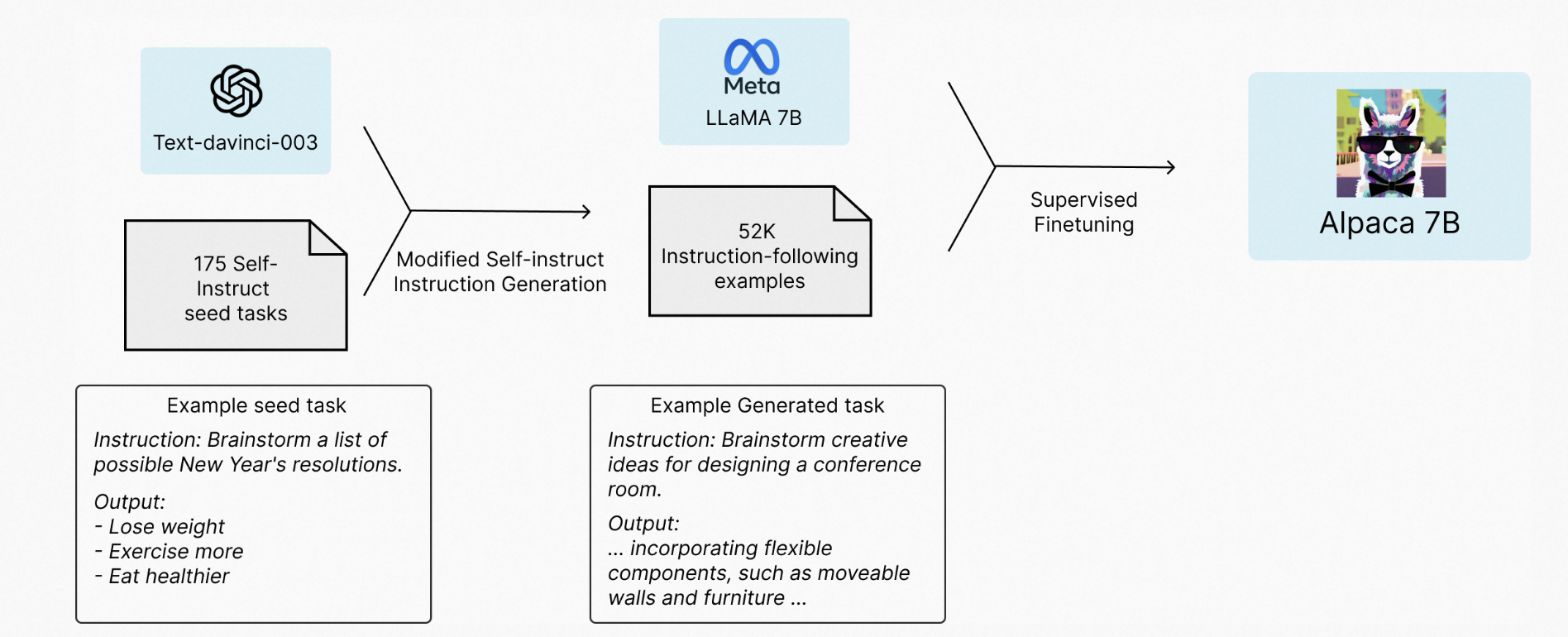
self-instruct
Self-Instruct: Aligning Language Model with Self Generated Instructions
基于指令框架降低人工标注指令数据的成本。
相关工作-人工标注:
- 人工设计相关指令任务
- 对当前指令任务进行标注(编写正确答案)
当前工作self-instruct:
- 人工设计175个表示不同任务的指令(完整输入输出),将这部分数据作为种子池
- 使用模型生成新的指令:6个人工指令+2个生成指令-》生成新的指令
- 对该模型生成的指令判断是否分类任务:prompt模板会根据是否是分类任务有所不同。
- 使用模型生成实例:输入优先以及输出优先(分类)两种输出策略。
- 对上述模型生成的数据进行过滤和后处理:ROUGE-L<0.7才加入-保证多样性,减少重复内容;排除一些无法处理的指令;过滤输入相同但输出不同的实例。
- 将经过过滤和后处理的数据添加到种子池中;
一直重复上述2到6步直到种子池有足够多的数据;
对于分类任务,如果先生成文本,后生成标签,模型会偏向于生成比较单一的结果。所以对于分类任务,是先生成随机的标签,然后再生成该标签对应的文本。
指标ROUGE-L:最长连续公共子串占比对两个字符串的比值,再通过F1计算
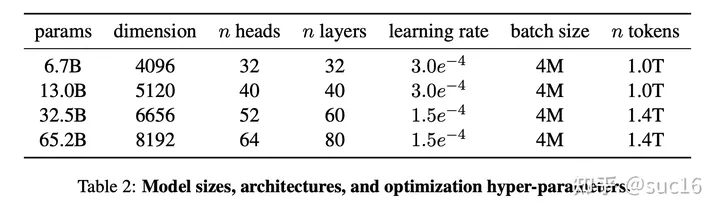
结论:GPT3+self-instruct性能与text-davinci-001接近;self-instruct是有一定性能提升的;数据集不大-252条指令
- Self-Instruct: Aligning Language Model with Self Generated Instructions
- NLP评估指标之ROUGE
In-Context learning
References
1.
大模型相关基础内容
算力区分
FLOPS(Floating-Point Operations Per Second) - 这是衡量计算机或其他设备执行浮点运算速度的基本单位,表示每秒钟可以执行多少次浮点运算(加、减、乘和除等运算)。FLOPS 以前通常用于衡量大规模科学计算和数值模拟等需要双精度浮点数计算的应用程序,现在也被用于描述AI高精度训练算力。
FP64:双精度浮点数,占用64位存储空间,通常用于大规模科学计算、工程计算等需要高精度计算的算法。
FP32:单精度浮点数,占用32位存储空间。与双精度浮点数相比,存储空间较小但精度较低,部分科学计算和工程计算也可以使用FP32,但通常也用于神经网络的前向推理和反向传播计算。
FP16:半精度浮点数,占用16位存储空间。存储空间更小但精度进一步降低,通常用于模型训练过程中参数和梯度的计算。
BF16: 用于半精度矩阵乘法计算(GEMM)的浮点数格式,占用16位存储空间。相对于FP16,在保持存储空间相同的情况下能够提高运算精度和效率。
TF32:TensorFLoat-32,是NVIDIA定义的使用TensorCore的中间计算格式。
INT8:8位整数,用于量化神经网络的计算,由于存储和计算都相对于浮点数更加高效,在低功耗、嵌入式系统和边缘设备等领域有着广泛的应用。用TOPS(Tera Operations Per Second,每秒处理的万亿级别的操作数)作为计算性能的单位。
INT4:4位整数,只能表示-8到7的16个整数。因为新的量化技术出现,追求更低的存储空间,减少计算量和更高的算力密度,而产生的新格式。
量化:本质上只是对数值范围的重新调整,可以「粗略」理解为是一种线性映射。
CUDA内核对INT8处理不是十分高效,INT8计算难以使得GPU核心饱和,且由于需要额外的量化开销,因此会减慢整体的推理速度。
参考
- 【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍-原博客
- int8速度慢原理分析
面经
https://zhuanlan.zhihu.com/p/643829565
https://zhuanlan.zhihu.com/p/643836163
https://zhuanlan.zhihu.com/p/643560888