2023.11.07-LONGLORA_ EFFICIENT FINE-TUNING OF LONG-CONTEXT LARGE LANGUAGE MODELS
每日一句: I cannot choose the best. The best chooses me.
研究背景与动机
核心是希望能够在有限的资源下能够扩充LLM的窗口。分别通过稀疏Attention(shift short Attention)和对模型的嵌入层一起微调实现微调逼近全参的效果。
类似于直接将计算量降低+LoRA+Embedding+PI扩充窗口
主要工作与贡献
分别从数据和策略两方面实现上下文窗口的扩充。
- 数据侧:缺少公开长文本对话数据,此前的一些数据都是“next-token-generation”的方式的非对话语料;重新收集高质量的长文本问答语料
- 策略:从注意力着手修改-shift short attention偏置短注意力;用稀疏attention代替稠密attention
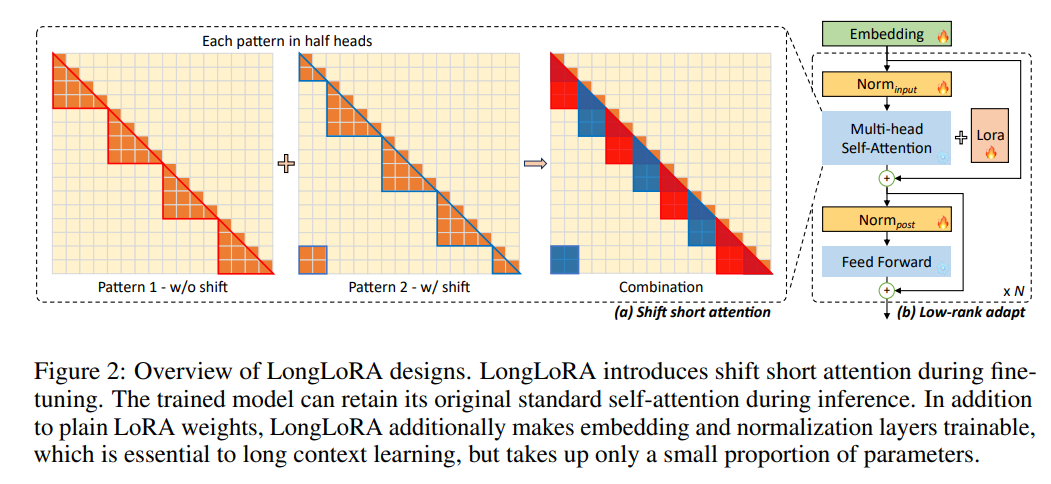
- LoRA训练基础上增加了对Embedding layer和Normalization layer的微调,实现达到和全参数调整的效果(解决LoRA无法在文本长度迁移取得良好效果的问题)