预训练模型学习
预训练模型
评估
评估预训练语言模型的优劣通常有以下几种方法:
困惑度(Perplexity):困惑度是一种常用的评估语言模型的方法,它可以用来衡量模型对新数据的预测能力。困惑度越低,表示模型对数据的拟合效果越好。
语言模型下游任务:语言模型下游任务是指在特定任务上使用预训练语言模型进行微调,以便更好地适应该任务。通常,如果预训练语言模型在下游任务上表现良好,则说明该模型具有较好的泛化能力和语言理解能力。
人类评估:人类评估是指通过人工判断预训练语言模型生成的文本是否符合语法、逻辑和语义等方面的要求。虽然这种方法比较费时费力,但是它可以提供更加客观的评估结果。
对抗样本攻击:对抗样本攻击是指通过对预训练语言模型输入进行修改,使其输出错误结果或误导结果。通过对抗样本攻击,可以评估模型的鲁棒性和安全性。
多样性和一致性:多样性和一致性是指预训练语言模型在生成文本时是否有足够的创造力和一致性。如果模型生成的文本过于单调或者不一致,可能会影响其应用价值。
训练效率和存储空间:除了以上几个方面,评估预训练语言模型的优劣还需要考虑其训练效率和存储空间等因素。一般来说,训练效率和存储空间越小,表示该模型越实用
ref
DeBERTa系列模型
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
研究背景
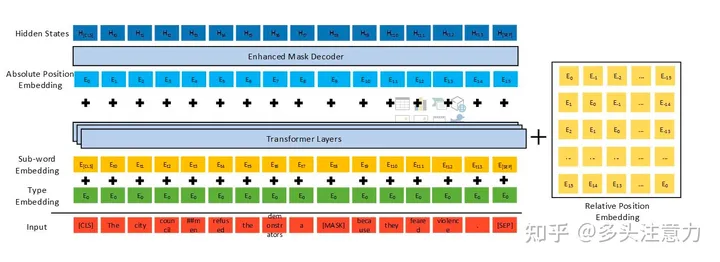
在Bert的基础上对模型进行改进,取得了不错的效果。
主要工作
deberta-1.0
解耦self attention
Disentangled Attention
一种新的相对位置编码方法;
这里的解耦是将位置信息和内容信息分别/交叉做attention,而这里的位置信息在Deberta中采用的是相对位置编码
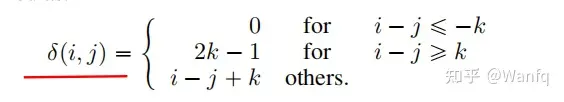
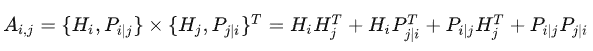
考虑绝对位置的MLM任务
- Enhanced Mask Decoder
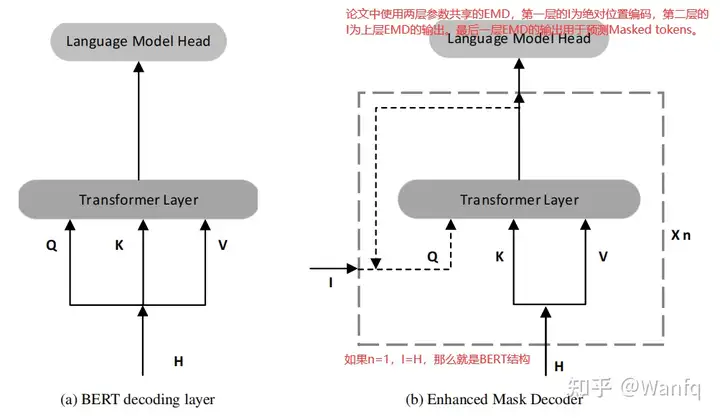
BERT结构存在预训练和微调不一致的问题,即预训练时是将最终的隐状态输入softmax层预测masked tokens,而微调时根据下游任务的不同其结构存在差异。
EMD将模型在预训练时的结构加以改变,其结构如上所示,其中H为之前Transformer层的隐状态,I可以是任何对于decoding有帮助的信息(例如:直接用H,绝对位置信息,之前EMD层的输出等)。
通过信息增加有助于调整需要的特征。预训练引入对抗训练
- SIFT(scale invariant fine tuning)
由于词向量的范数在不同的词和模型中有所不同,若模型较大,方差会变得更大,从而导致虚拟对抗训练的不稳定。
所以在首先要对词向量归一化为随机向量,然后再对词向量施加扰动进行虚拟对抗训练。
References
基础PLM系列
基础知识
CLS标识
References
RoBERTa模型
- 核心思想
通过更好地训练BERT可以达到超过其他新的预训练语言模型的效果
- 核心改动
- 更大的 Batch Size (最大的 Batch Size 达到了 32K)
- 去掉 Next Sentence Prediction (在建模时需要注意这一点)
- 采用更大的预训练语料 (超过100G)
- Dynamic Masking (BERT在训练时可能会固定地把一个地方 Mask几遍)
XLNET模型
- 研究背景
Bert采用AE(自编码)方法存在的问题:
- 有个不符合真实情况的假设:即被mask掉的token是相互独立的。
- BERT在预训练和精调阶段存在差异
- 改进方案
- 对序列重新组合,让模型能够学习如何聚集所有位置的信息,Permutation Language Modeling Transformer-XL,主要用于解决长文本的问题
- Two-Stream Self-Attention,由于前面的排序重组会导致同一序列不知道预测什么内容的情况,为了解决这一问题模型加入了位置信息。
- 借鉴RNN,提出带有记忆能力的Transformer-XL
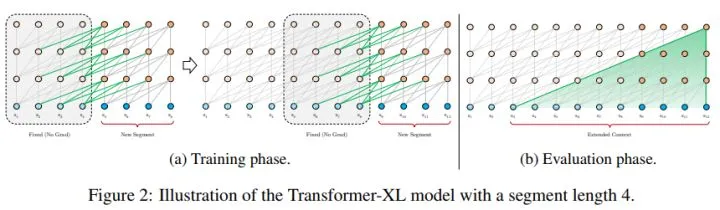
- 增加了多片段建模的方法,判断两个token是否在一个片段中。具体是在计算注意力权重的同时针对query额外计算一个权重,加到原本的权重上去。
- 增大了预训练阶段使用数据的规模
References
ERNIE模型
- ERNIE 1.0
改进了masking的策略
- 基于短语的
- 基于实体的
- ERNIE 2.0
核心:提出了一个预训练框架,可以在大型数据集上进行增量训练
- 预训练连续学习,能够在学习新的任务的时候记住之前任务的结果。具体实现,当前工作分别构建了词法级别、语法级别和语义级别的预训练任务
- encoder权重不共享
- 用不同的task id标记预训练任务
References
ALBERT
- 核心思想:
权重共享 输入层的优化 Sentence Order Prediction
- 工作与总结:
ALBERT的核心思想是采用了两种减少模型参数的方法,比BERT占用的内存空间小很多,同时极大提升了训练速度,更重要的是效果上也有很大的提升!
- 具体工作细节:
Factorized Embedding Parameterization
原Bert-base由12层Transformer中的encoder组成,经由bert获得的向量表示维度H与其一开始的Embedding层维度E一致,但是其实没有必要,E大小可以根据实际的词表大小调节,此时若要保持H维度大小的输出仅需E*H的变换即可。
Cross-layer Parameter Sharing
共享所有层的参数,主要是attention和FeedForward参数,该手段则是通过共享部分attention和Feedforward参数实现参数量的减少,此时效果会有所下降,但通过增加H的维度实现效果提升-推理速度不变
Sentence Order Prediction
NSP预训练任务将Topic Prediction和Coherence prediction融合起来了,只要判断两个句子是不是一个Topic的就能对预训练任务出个大概的结果了。论文通过将负样本换成同一篇文章中的两个逆序句子,来消除Topic prediction,提升预训练任务的学习效果。
参数量以及具体效果分析:
bert-base:108M
albert-base:89M(no-shared),12M(shared)
参数量减少了,但是并没有对模型推理速度这一块有较大的提升。主要还是减少了模型的参数量加快模型的训练,并没有对推理有太好的效果提升。
References
ELECTRA模型
- 核心思想:采用对抗训练提升模型训练效果
- 具体实现:通过 MLM 训练 Generator Discriminator 负责区分 Generator 生成的 token 是否被替代
- 其他改进:采用权重共享