生成式模型学习
BART-预训练方法
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
研究背景
文本理解任务,大部分的工作范式都是采取语言模型预训练+下游任务finetune这一种方式。BART模型相当于采用了BERT+GPT的模型结构兼顾上下文语境信息的同时带有自回归特性。BART相当于是建立在seq2seq Transformer model的基础上,使其分别能够适用于文本生成和文本理解的任务,并在这些任务都实现了较好的性能。
主要工作
- 模型结构BERT+GPT,兼顾理解与生成;
- BART的预训练任务是恢复基于随机噪声破坏后的文本;
- 具体的noise有5种:
- token mask:单个掩码
- token deletion:随机删去token
- text infilling:随机将一段连续的token(称作span)替换成一个[MASK],span的长度服从$$ \lambda=3 $$的泊松分布。注意span长度为0就相当于插入一个[MASK]。
- Sentence Permutation: 将一个document的句子打乱
- Document Rotation: 从document序列中随机选择一个token,然后使得该token作为document的开头
- 适用于不同的下游任务
References
- 【论文精读】生成式预训练之BART
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
T5
BLOOM
GPT
References
CPT
解码算法
greeedy-贪心
直接logit最大
beam search
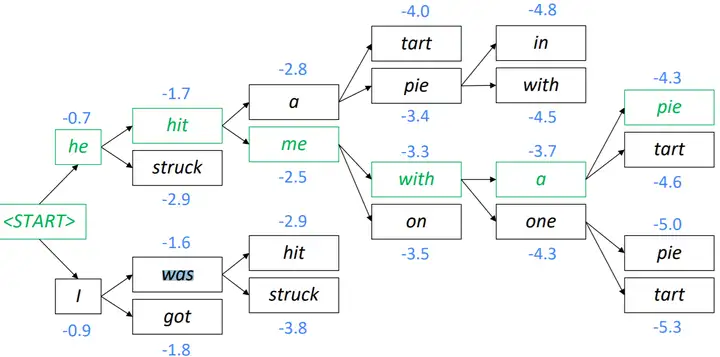
始终从k条最优序列中选择K个最好的beach search需要选择beam size,越小越接近greedy,beam size=1就等价于greedy. 越大beam size 计算代价就越大,并且有些试验告诉我们太大的beam size可能会有更差的效果。一般来说beam size=3是一个不错的trade off。
sampling-based
每次算出最有可能的token集合,然后按照某种概率分布从中采样n个候选答案。和beam search区别是用softmax代替argmax,通常用于开放式或者需要创造性的生成任务上,比如写故事/写诗之类。
softmax temperature
Softmax temperature是在softmax层上加了一个超参数,可以用来平衡diverse的。Softmax temperature是调节softmax的技巧,它不能单独使用,要配合greedy search或者beam search做decoding.