传统NLP模型学习
Word2Vec模型
模型作用
对词语实现向量化表示,获得词向量。将one-hot表示转换成为稠密向量表示。
实现与细节
- 具体模型实现
skip-gram:一对多映射
cbow:多对一映射
- 实现方式
通过词向量的点积计算,获取词与词之间的相似性;并采用softmax映射到概率值。通过梯度下降,调整词向量的表示,进而获得良好的词向量。
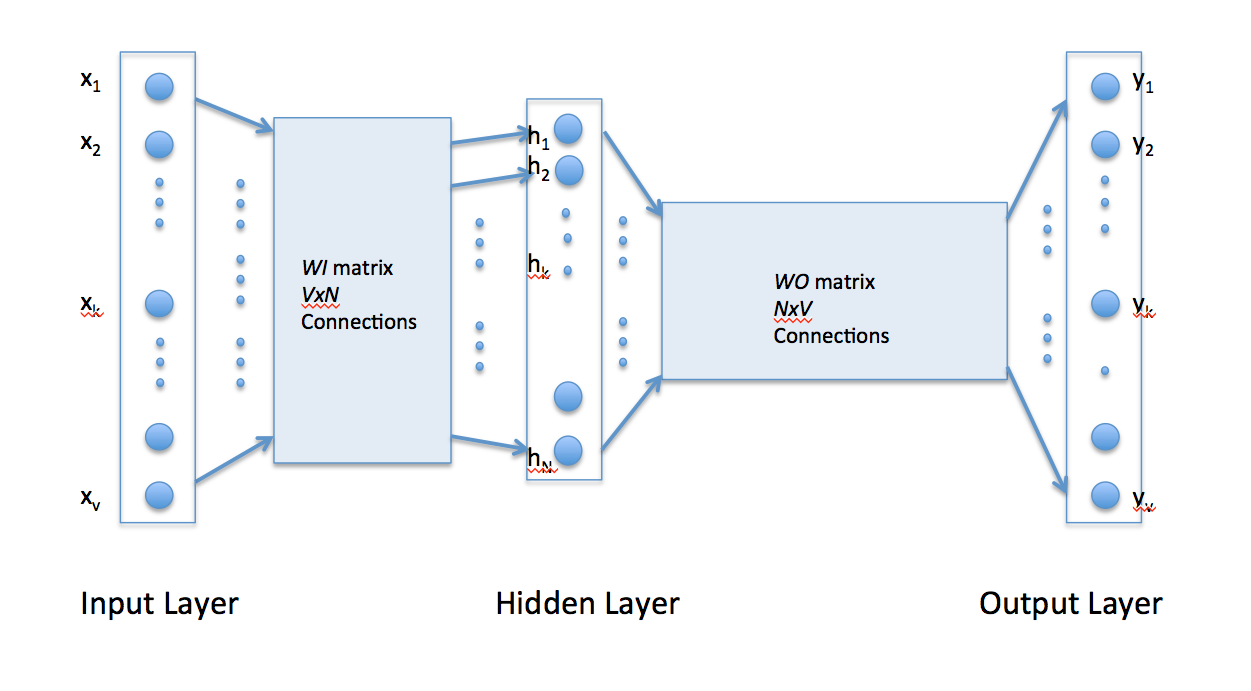
两个网络权重行向量和列向量分别表示当前的词向量。
- word2vec训练加速:
由于计算概率值时,需要对整个单词表做乘积和exp运算,因此计算量耗费较大。
高频词抽样;负采样提高训练效率;层级softmax
Tricks
- 负采样
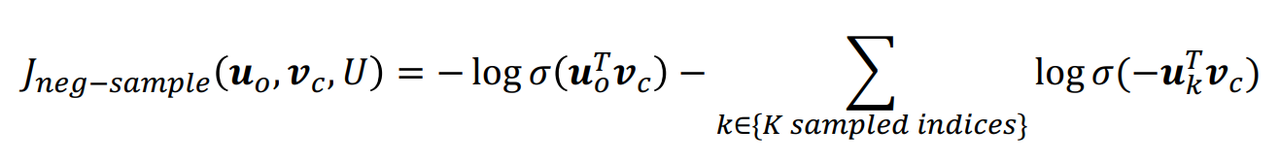
从单词表中按照一定规则随机选出一部分负样本,再进行概率计算,避免了在整个词汇表上的计算。并将原本的指数计算转换成sigmoid函数,也减小了这部分的计算量。
计算公式:
$$
\frac{\partial{J_{neg-sample}(\boldsymbol v_c,o,\boldsymbol U)}}{\partial\boldsymbol v_c} \= \frac{\partial (-log(\sigma (\boldsymbol u_o^T\boldsymbol v_c))-\sum_{k=1}^{K} log(\sigma (-\boldsymbol u_k^T\boldsymbol v_c)))}{\partial \boldsymbol v_c} \= -\frac{\sigma(\boldsymbol u_o^T\boldsymbol v_c)(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))}{\sigma(\boldsymbol u_o^T\boldsymbol v_c)}\frac{\partial \boldsymbol u_o^T\boldsymbol v_c}{\partial \boldsymbol v_c} - \sum_{k=1}^{K}\frac{\partial log(\sigma(-\boldsymbol u_k^T\boldsymbol v_c))}{\partial \boldsymbol v_c} \= -(1-\sigma(\boldsymbol u_o^T\boldsymbol v_c))\boldsymbol u_o+\sum_{k=1}^{K}(1-\sigma(-\boldsymbol u_k^T\boldsymbol v_c))\boldsymbol u_k
$$
References
glove模型
GloVe:Global Vectors for Word Representation
两者最直观的区别在于,word2vec是“predictive”的模型,而GloVe是“count-based”的模型。
相比Word2Vec,GloVe更容易并行化,所以对于较大的训练数据,GloVe更快(大数据集训练更快)。
GloVe的本质是对共现矩阵进行降维。
实现流程概括:
- 构建共现矩阵
根据语料库构建共现矩阵,每个元素代表当前词(行)与其他词共现的次数(在特定窗口大小内)。并且增加了衰减函数计算权重,距离越远权重越小。
- 词向量与共现矩阵的近似关系
$$
w_{i}^{T}\tilde{w_{j}} + b_i + \tilde{b_j} = \log(X_{ij})
$$
- 构造损失函数
$$
J = \sum_{i,j=1}^{V} f(X_{ij})(w_{i}^{T}\tilde{w_{j}} + b_i + \tilde{b_j} – \log(X_{ij}) )^2
$$
需要在原有的基础上增加一个分段函数调节损失。
References
LSTM模型
BiLSTM模型
References
N-gram语言模型
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
根据窗口大小不同,每次截取N个词构成的内容,然后依照one-hot表示得到对应的特征向量
Refs
词袋模型
选定文本内一定的词放入词袋,统计词袋内所有词在文本中出现的次数(忽略语法和单词出现的顺序),将其用向量的形式表示出来。
词袋选词:设置一些停用词;对相近词进行词干提取,只将词干放入词袋;词的同类变形,则通过词形还原将同一个特征加入词袋;
通过TF-IDF调整词袋模型得到的词频向量矩阵