ViT系列模型学习
ViT模型
ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
研究背景
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究.
ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果.
但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。
CNN具有两种归纳偏置,一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变形(translation equivariance).当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型
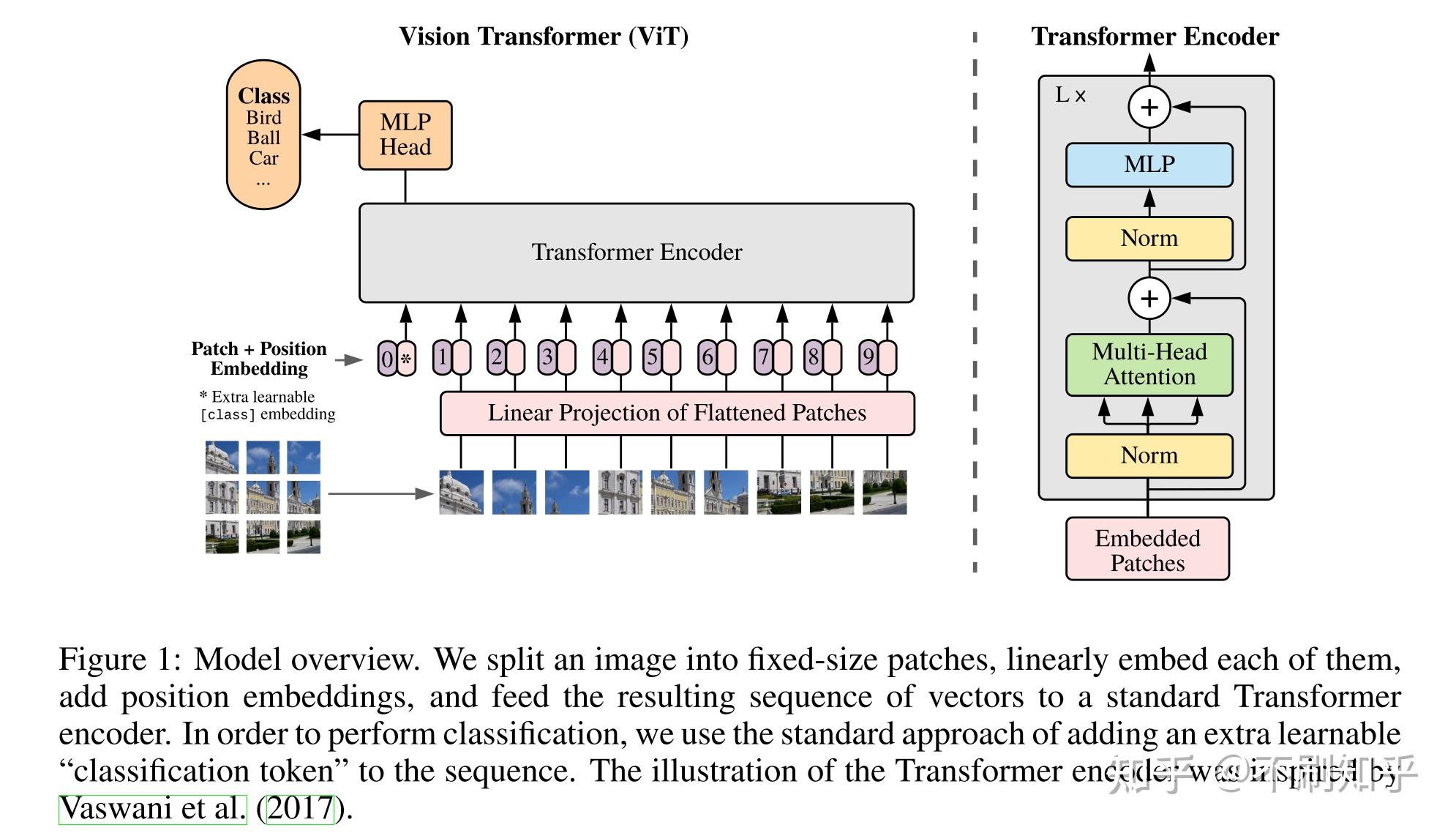
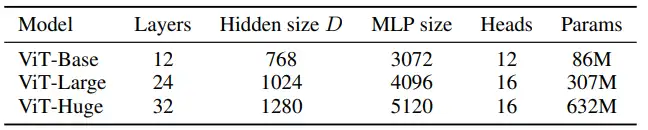
主要工作
- 输入:将图像拆成N个$p*p$的小patch,然后将每个patch当成是一个token;
- 具体到每个patch则是直接进行flatten之后直接经过线性映射得到D维Embedding表示;
- 这里的pos-embedding按照实验是直接采用1-D位置编码,按照从左到右的块排序
References
MLP-Mixer
MLP-Mixer: MLP-Mixer: An all-MLP Architecture for Vision
研究背景
ViT作者团队出品,在CNN和Transformer大火的背景下,舍弃了卷积和注意力机制,提出了MLP-Mixer,一个完全基于MLPs的结构,其MLPs有两种类型,分别是channel-mixing MLPs和token-mixing MLPs,前者独立作用于image patches(融合通道信息),后者跨image patches作用(融合空间信息)。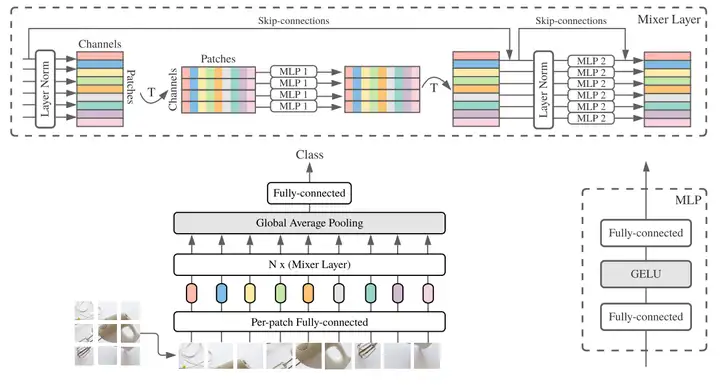
主要工作
- 类似于ViT的模型结构训练方式,也需要将图像信息打成多个块;
- 提出两种MLPs结构
token-mixing MLPs:允许信息在空间维度交互,独立作用于每一个channel,作用于列,融合不同token的特征channel-mixing MLPs:允许信息在通道交互,独立作用于每一个token,作用于行,融合不同channel的特征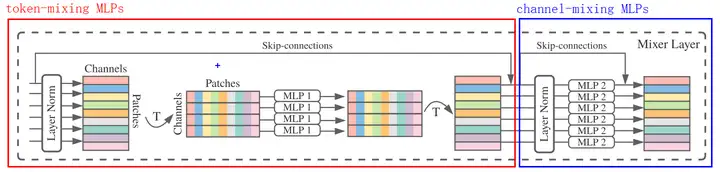
- 因为token-mixing MLPs对输入tokens的顺序非常敏感,Mixer不适用positional encoding
- 每个Mixer Layer中token-mixing MLPs共享参数,channel-mixing MLPs同样共享参数
- 当在大规模数据集上预训练(100million images),Mixer可以接近CNNs和Transformers的SOTA表现,在ImageNet上达到87.94%的top-1 accuracy;当在更小规模数据集上预训练时(10million),结合一些regularization techniques,Mixer可以接近ViT的性能,但是稍逊于CNN
References
Swin-Transformer模型
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
研究背景
- 核心思路:披着CNN的Transformer。
- 挑战:ViT性能并没有超过其他的工作;基于全局自注意力计算会导致计算量较大;强行分割patch其实破坏了原有的邻域结构,不再具有卷积的空间不变性。
- 通过提出一种称为shifted window的方法来解决以上问题。
主要工作
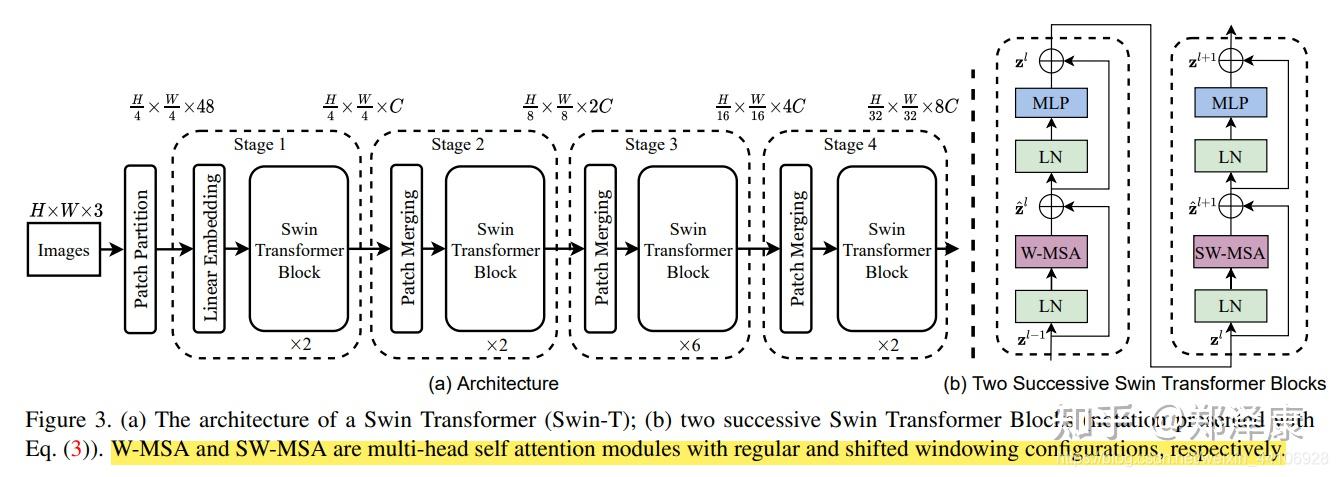
结构大致介绍:
- 在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。
- 在每个Stage里,由Patch Merging和多个Block组成。
- 其中Patch Merging模块主要在每个Stage一开始降低图片分辨率。
- 而Block具体结构如上图所示,主要是LayerNorm,MLP,Window Attention 和 Shifted Window Attention组成
Patch Embedding
将图片划分为若干4*4的patch,使用线性变换来将patch变为Embedding向量,这一步和ViT是一样的。但是注意,这里的patch比ViT的14*14小了很多。Patch Merging
该模块的作用是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。Window Attention
传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量. 主要计算区别在于:在原始计算Attention的公式中的Q,K时加入了相对位置编码。Shifted Window Attention
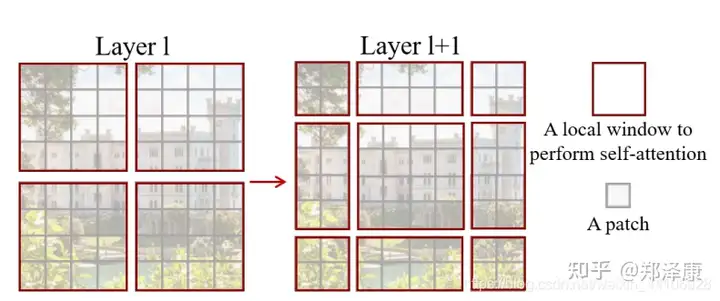
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。
由于这一操作会使得window变化,因此实际操作中通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
References
Swin-Transformer_v2模型
主要是解决模型上规模的问题,有几个主要的改动:
- 把每个Block里的LN从前面换到了后面,来解决深度增加之后训练不稳定的问题
- 把原来的scaled dot attention换成了scaled cosine attention,也是为了解决训练不稳定的问题(否则可能被某些像素对的相似度主导)。
- 改进相对位置偏置。V1版里这个模块是用一个规模跟窗口大小M相关可学习参数矩阵来处理的,如果预训练和finetune时M大小改变,就用插值来生成原来不存在的值。V2版首先是引入了一个小网络来取代参数矩阵,其次是将相对位置从线性空间换到了对数空间,通过取对数压缩空间差距来让M变化时的过渡更加顺滑