大模型加速相关内容
- 模型训练以及推理中的显存占用计算与混精优劣
- FlashAttention
- Multi-Query Attention
- vLLM:PagedAttention
- xformer
- DeepSpeed
- Sparse Attention
模型训练以及推理中的显存占用计算与混精优劣
按照参数量来计算
当采用fp16训练得到的模型:
1个字节8bit,fp16=2个字节,10B的模型=20GB
n B模型 推理需要2n GB显存才能将模型加载;训练采用Adam优化器,则下限内存:2+2+12(4+4+4-模型参数
梯度、优化器状态)-16n GB
混精优劣:速度快,但容易溢出(fp16),并且计算softmax需要切回fp32;bf16 损失的精度被证明不怎么影响收敛-A100及以后的显卡
References
FlashAttention
相关简述
直接结论:速度更快,内存消耗更小
FlashAttention的运行速度比PyTorch标准注意力快 2-4 倍,所需内存减少5-20倍。
为了避免从HBM(High Bandwidth Memory)中读取和写入注意力矩阵,flashattention希望实现在不访问整个输入的情况下计算softmax的缩减,并且反向传播中不能存储中间注意力矩阵。
具体实现:
- 将输入分割成块,并在输入块上进行多次传递,从而以增量方式执行softmax缩减。
- 不使用中间注意力矩阵,通过存储归一化因子来降低HBM的内存消耗。在后向传播中快速重新计算片上注意力,虽然增加了计算量,但速度更快内存更高(大大降低HBM的访问)
代码实现
1 | ''' |
References
- FlashAttention图解(如何加速Attention)
- 论文分享:新型注意力算法FlashAttention
- FlashAttention2详解(性能比FlashAttention提升200%) - 知乎 (zhihu.com)
Multi-Query Attention
References
vLLM:PagedAttention
背景:LLM模型在推理过程中,key、value通常会存在GPU中用于生成下一个token。这部分显存占用很大且由于大小是动态变化的,因此会出现过度预留显存导致显存浪费
- 借鉴:操作系统中的虚拟内存和分页经典思想
- 实现:将每个序列的KV cache进行分块,每个块中包含固定的tokens的key和value。分块之后这部分张量不再需要连续的内存,使得显存的利用率更高。
- 特性:memory sharing
- 当用单个 prompt 产出多个不同的序列时,可以共享计算量和显存。
- 通过将不同序列的 logical blocks 映射到同一个 physical blocks,可以实现显存共享。
- 为了保证共享的安全性,对于 physical blocks 的引用次数进行统计,并实现了 Copy-on-Write 机制。
- 这种内存共享机制,可以大幅降低复杂采样算法对于显存的需求(最高可下降55%),从而可以提升2.2倍的吞吐量。
References
xformer
References
DeepSpeed
- 推理自适应并行性(
Inference-adapted parallelism):允许用户通过适应多 GPU 推理的最佳并行策略来有效地服务大型模型,同时考虑推理延迟和成本。
模型训练权重可以加载指定的并行度,另外会为模型插入需要的通信代码协助多GPU通信
- 针对推理优化的 CUDA 内核(
Inference-optimized CUDA kernels):通过深度融合和新颖的内核调度充分利用 GPU 资源,从而提高每个 GPU 的效率。
深度融合就是将多个运算符融合到一个内核中;针对推理优化了GEMM操作。
- 有效的量化感知训练(
Effective quantize-aware training):支持量化后的模型推理,如 INT8 推理,模型量化可以节省内存(memory)和减少延迟(latency),同时不损害准确性。
通过量化混合和INT8推理内核实现,量化混合就是简单地将 FP32 参数值转换为较低精度(
INT4、INT8等),然后在权重更新期间将它们存储为FP16参数(FP16数据类型,但值映射到较低精度);高性能INT8推理就是加载INT8参数到主存中,加载到共享内存中就会转换成FP16
另外为了减少大模型的训练时间,框架提供了三种技术:
- 新的压缩训练策略:大模型训练期间,通过
Progressive Layer Dropping利用 Transformer 层中粗粒度的稀疏性来降低训练成本,从而在不影响准确性的情况下使收敛速度提高 2.8 倍。 - 1 bit 的 LAMB:实现了大模型训练的高效通信,通信量减少 4.6 倍,即使在具有低带宽互连的集群中也能加速大型模型的训练。
- DeepSpeed Profiler 性能工具:通过显示模型复杂性和训练效率,以帮助用户识别性能瓶颈。
DeepSpeed 通过系统优化加速大模型推理 - 知乎 (zhihu.com)
ZeRO-零冗余优化器
总体:ZeRO1是优化器切分到各卡,ZeRO2是梯度切分到各卡,ZeRO3是模型参数切分到各卡。OFFLOAD是用一部分内存来补充显存的不足。
ZeRO:Zero Redundancy Optimizer
深度学习模型的大部分内存消耗可以归结为以下三种(文中称为OPG状态):
- O:优化器状态(例如Aadam优化器中的的momemtum、variance)
- G:梯度
- P:参数
ZeRO通过在数据并行进程之间划分OGP模型状态而不是复制它们来消除数据并行进程之间的内存冗余,在训练过程中采用动态通信调度,保持了和数据并行基本一致的计算粒度和通信量,从而保持了计算/通信效率。
具体实现是对OPG状态分别进行优化:
优化器优化: 每个GPU都保存全部的参数和梯度,但只保存1/Nd的优化器变量
优化器+梯度优化:只保存1/Nd的梯度和优化器变量
优化器+梯度+参数优化: 只保存1/Nd的参数、梯度和优化器变量
论文解读系列第十三篇:ZeRO——面向万亿级参数的模型训练方法 - 知乎 (zhihu.com)
使用说明
在Transformers中集成DeepSpeed - 知乎 (zhihu.com)
应用实例
通过使用HuggingFace的accelerate库实现deepspeed方法
LLM-tuning/llama_tuning/lora_deepspeed at master · jiangxinyang227/LLM-tuning (github.com)
推理加速
Getting Started with DeepSpeed for Inferencing Transformer based Models - DeepSpeed
Refs
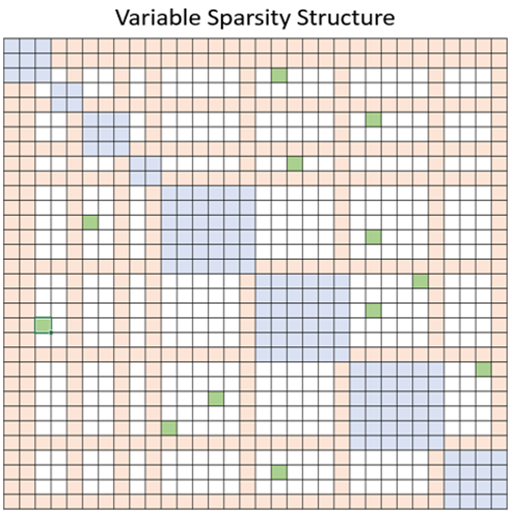
Sparse Attention
自注意力机制的计算量$O(n^2)$-需要对任意两个向量计算相关度;因此,为了节省现存,基本的思路就是减少关联性的计算.
Atrous self attention
类似于膨胀卷积,要求每个元素只跟它相对距离为k,2k,3k,…
的元素关联.相当于每个元素只跟大约n/k
个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了$O(n^2/k)$,也就是说能直接降低到原来的1/k.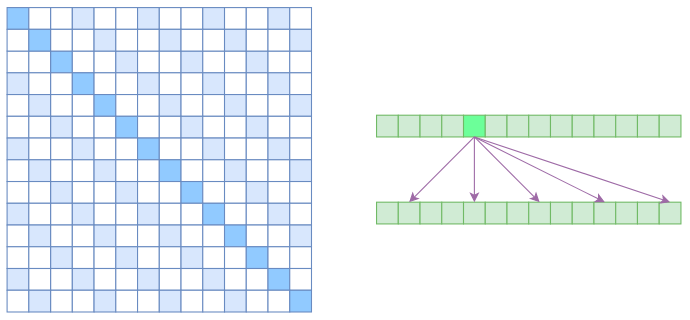
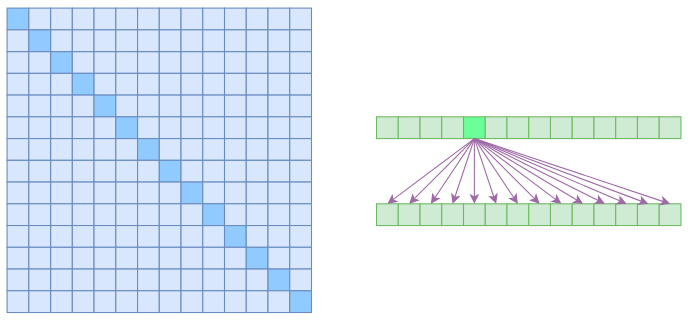
Local self attention
就直接是字面意思,将相对距离超过k的注意力全部都设为0.
对于Local Self Attention来说,每个元素只跟2k+1
个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了O((2k+1)n)∼O(kn)了,也就是说随着n而线性增长,这是一个很理想的性质——当然也直接牺牲了长程关联性。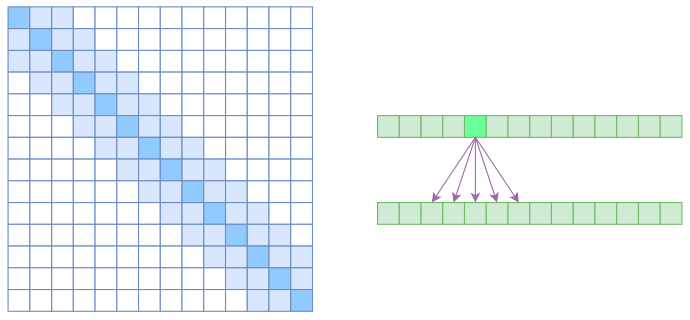
sparse self attention
相当于是atrous+local,实现了除了相对距离不超过k的、相对距离为k,2k,3k,…的注意力都设为0,这样一来Attention就具有“局部紧密相关和远程稀疏相关”的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
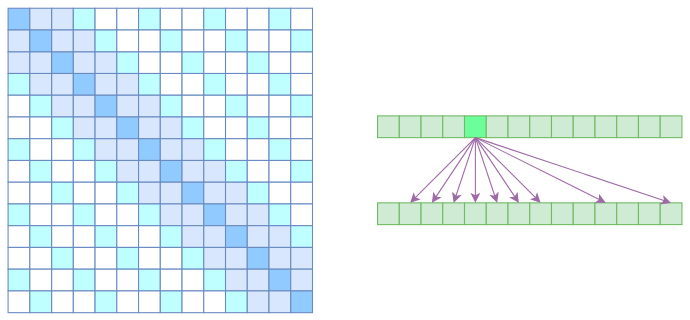
deepspeed-sparse attention
随机、局部、全局三种注意力的随机组合