思维链
本文主要介绍CoT相关的一些方法和技术
CoT
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
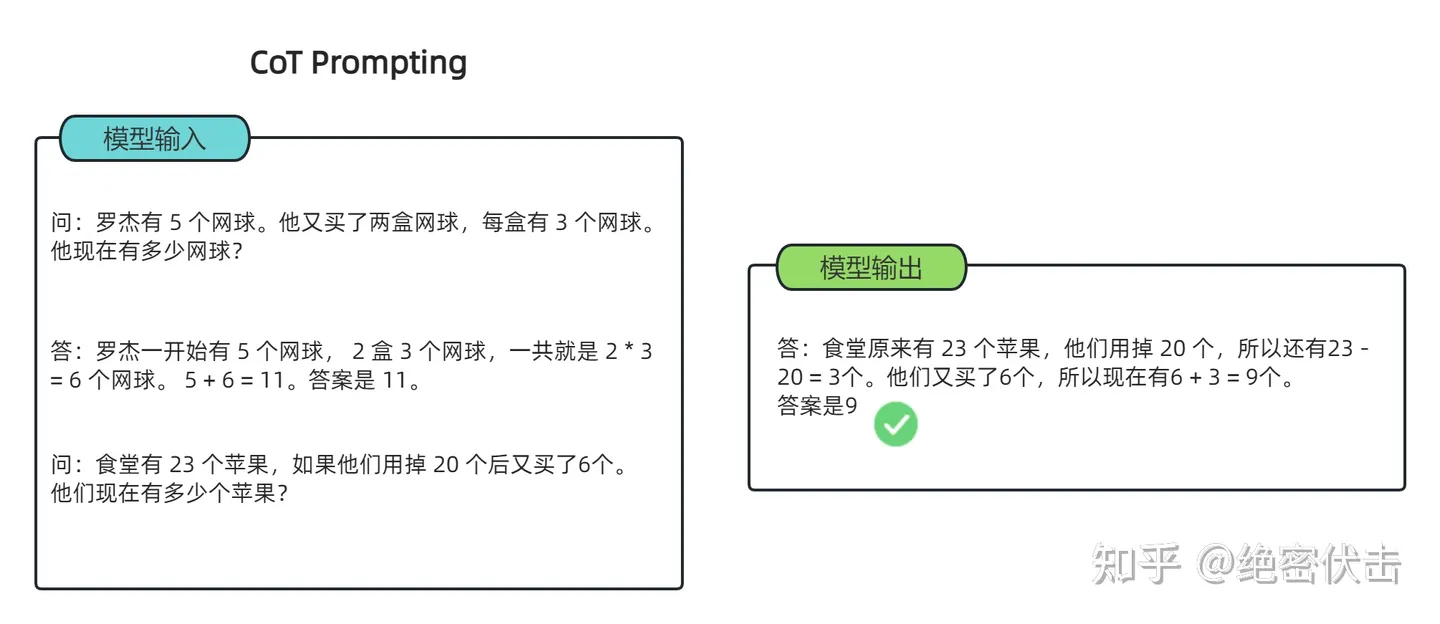
简单来说就是将原本的问题,经过多个中间步骤最终获取答案,实现更好的推理。
具体实现效果:常识推理能力赶超人类;数学逻辑推理能力大幅度提升;LLM可解释性更强。
- Zero-shot-CoT
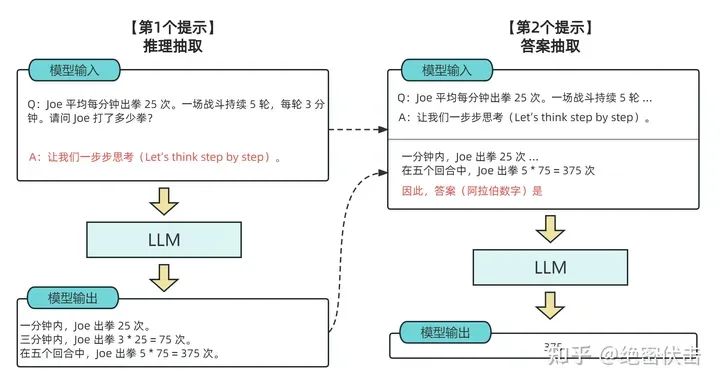
零样本思维链通过引入与样本无关指示,来实现自我增强
- 多数投票提高CoT性能——自洽性(Self-consistency)
其实核心就是对生成的多个结果选择取多数的答案,这一个可以直接通过控制temprature和Top-K来实现,很显然这会使得时间会变长。
- LtM(Least to Most prompting)
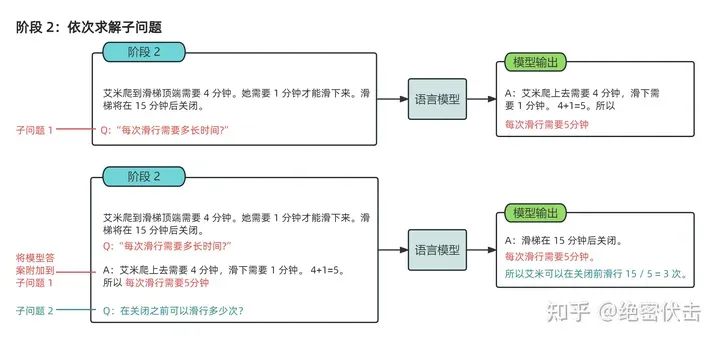
将问题按步骤拆分成多个子问题,解决完多个子问题后回答最终问题。具体训练就是分为多个CoT阶段实现。
- Flan-PaLM/T5:CoT + Finetuning
Flan-T5:在超大规模的任务上对模型进行微调,使得单个模型在1800多个NLP任务上都能够有很好的表现。
微调方法就是在加入CoT数据。其核心是对多任务数据的统一。
实现流程:
- 收集带有标签的数据,将每个任务定义为<数据,任务类型>
- 对数据的形式进行改写,比如改写成CoT的形式;并对是否需要CoT和few-shot,进行组合构造
- 训练过程:恒定的学习率以及 Adafactor 优化器;同时将多个训练样本打包成一个训练样本,通过特殊结束token进行分割。
结论:
- 微调有效果,模型越大越好,任务越多越好
- 混杂CoT很重要
- 提升小模型的推理能力:Fine-tune-CoT
旨在利用大模型思维链推理能力指导小模型解决复杂问题。
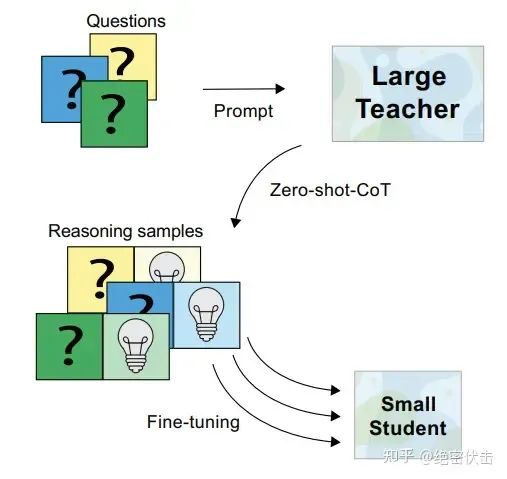
简单的说就是用ChatGPT这类大模型生成CoT数据,然后再喂给小模型进行微调。同时该方法需要生成尽可能多的数据。
CoT的局限性
- 思维链只有在模型规模足够大的时候才适用,如何实现小模型的思维链应用是值得探索的方向
- 应用领域有限,当前的实验结果只是在部分领域有所评估。另外,思维链只是提高模型的推理能力,但不代表模型真正理解内在的逻辑。