大模型基础模型
不同的大模型
LLaMA模型
LLaMA: Open and Efficient Foundation Language Models
研究背景
希望通过完全公开的数据集,更小的模型,实现比起更大模型的效果。
本文主要是在预训练数据、模型结构上做了相应的改进,为了提高训练速度也提出了一些相关的工作
主要工作
- 数据处理-在七个开源数据集上做数据预处理,主要是消除重复数据、过滤低质量内容(启发式过滤、n-gram语言模型过滤)
- 模型结构-在原有基础上分别增加了Pre-norm(RMSNorm)、SwiGLU激活函数、RoPE(旋转位置编码)
- 提速-Flashattention(用于提高显存的使用效率)
模型参数:
llama-7B:词表大小-32k,word_embedding-4096,head-32,layer-32
实现中QKV矩阵没有用偏置参数;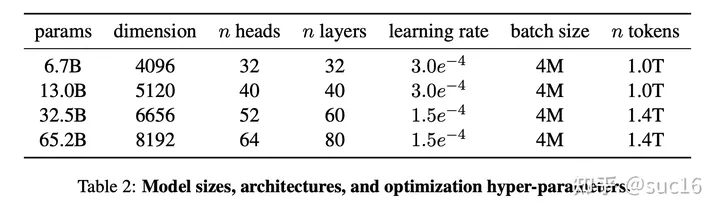
结论:
1)在阅读理解、代码生成领域,优于GPT-3或者PaLM模型。
2)在数学推理领域表现欠佳,作者给出的原因是没有在数学数据上进行过finetune。
3)在大规模多任务语言理解领域表现欠佳,不如Chinchilla-70B和PaLM-540B模型,原因是LLaMA在预训练数据集中,仅仅使用了很少一部分书籍和专业论文(177G VS 其他模型的2TB)。
References
LLaMA 2
Llama 2模型的主要特点和升级如下:
提供了7B、13B和70B参数三个规模的版本。
70B参数版本使用了分组查询注意力(GQA),提升了推理性能。
发布了专门针对聊天进行微调的Llama 2-Chat模型,效果与ChatGPT相当。
相比Llama 1,训练数据量增加40%,上下文长度加倍到4096,采用了更强的数据清理。
在多项推理、编码、知识测试的基准上,Llama 2的表现优于其他开源语言模型。
Llama 2-Chat通过强化学习从人类反馈中继续提升,注重模型的安全性和帮助性。
Llama 2主要针对英文优化,由于词表大小限制,直接应用于中文效果一般,需要进行中文特定的增强训练。
References
- 【LLM系列之LLaMA2】LLaMA 2技术细节详细介绍!
- 【LLM】Meta LLaMA 2中RLHF技术细节
- 【LLM系列之LLaMA2】LLaMA 2技术细节详细介绍! - 知乎 (zhihu.com)
Chinese LLaMA
扩展词表,将中文token添加到此表中,提高中文编码效率,具体实现:
- 中文语料上使用Sentence Piece训练一个中文tokenizer,使用了20000个中文词汇。然后将中文tokenizer与原始的 LLaMA tokenizer合并起来,通过组合二者的词汇表,最终获得一个合并的tokenizer,称为Chinese LLaMA tokenizer。词表大小为49953。
- 为了适应新的tokenizer,将transformer模型的embedding矩阵从 V*h 扩展到 V’*h ,新加入的中文token附加到原始embedding矩阵的末尾,确保原始词表表的embedding矩阵不受影响。(这里输出层应该也是要调整的)
- 在中文语料上进一步预训练,冻结和固定transformer的模型参数,只训练embedding矩阵,学习新加入中文token的词向量表示,同时最小化对原模型的干扰。
- 在指令微调阶段,可以放开全部模型参数进行训练。
中文tokenizer-扩展embedding矩阵-预训练只训练embedding矩阵-指令微调,放开全部模型参数进行训练
参考
1.大语言模型综述<演进,技术路线,区别,微调,实践,潜在问题与讨论>
alpaca模型
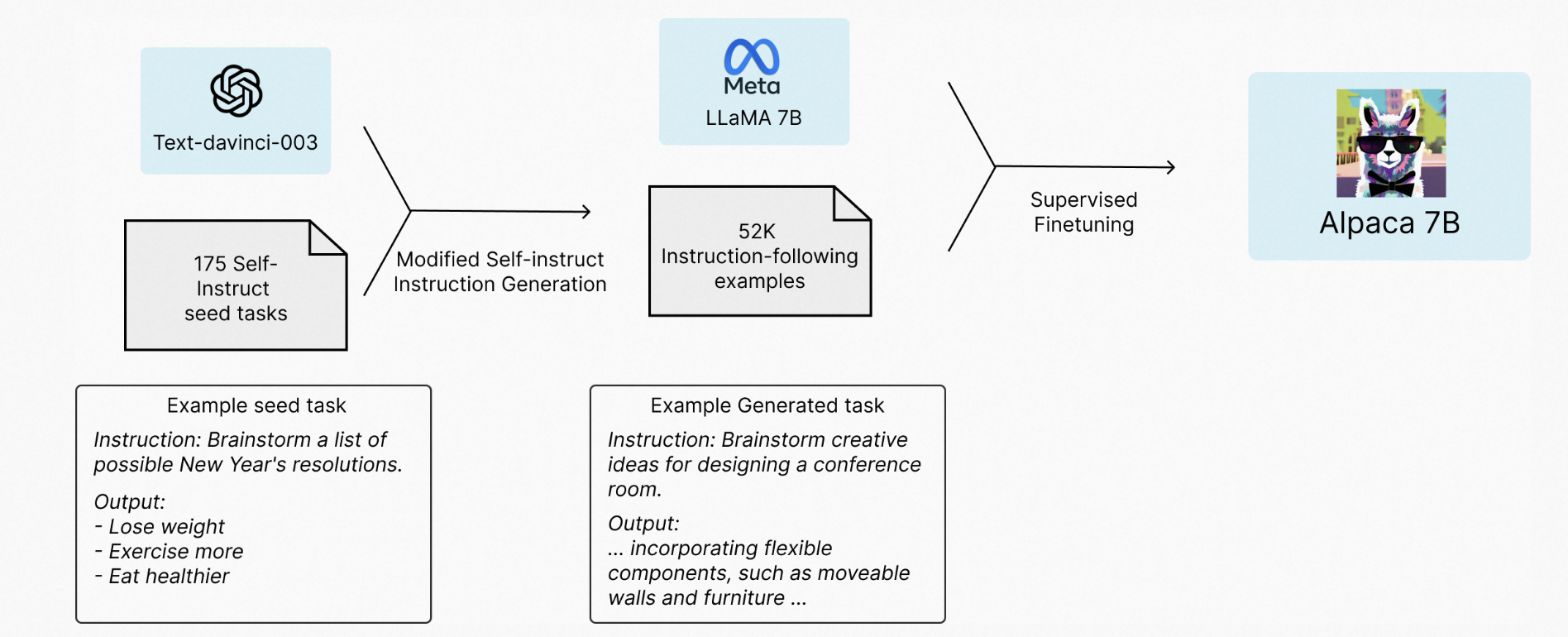
Alpaca: A Strong, Replicable Instruction-Following Model
基于指令调优的LLaMA模型,实现类ChatGPT大模型的训练步骤-SFT、Reward Model、RLHF
研究背景
关键词概括:指令调优、容量小、易复现、成本低
实现方式:即指令调优,通过设计相应的训练方法实现模型性能的提升
主要工作
基于text-davinci-003的接口以及self-instruct技术生成对应的高效指令用以微调LLaMA模型
References
ChatGLM模型
双语对话模型、6B模型
背景:
- 自回归模型:GPT-无条件生成
- 自编码模型:BERT-NLU
- encoder-decoder:T5-条件生成
综合以上GLM模型基于autoregressive blank infilling方法
GLM框架:
- AE:input随机删除连续token(mlm)
- AR: 顺序重建连续token
- span shuffling + 二维位置编码技术
- 通过改变缺失spans的数量和长度,自回归空格填充目标可以为条件生成以及无条件生成任务预训练语言模型。
具体细节
- 自回归空格填充任务
任务设计:
- 自注意力掩码
对文本片段采样(采用泊松分布采样span长度与BART参数一致),先得到挖空之后的文本parta(相当于掩码操作);
然后对所有采样片段随机排列(捕获不同片段之间的依赖关系)拼接到parta之后,用特殊字符切分不同的位置。
- 位置编码
二维位置编码:
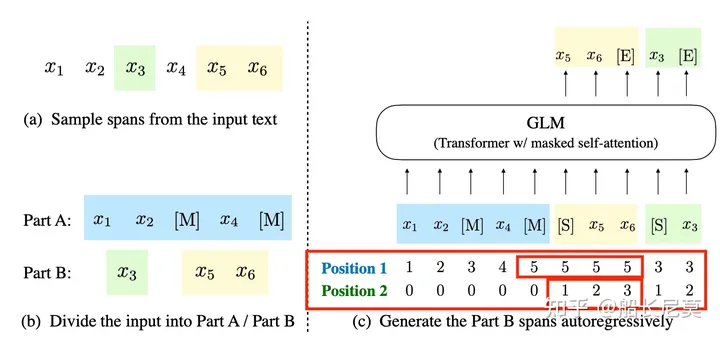
从图像来看,AE学习parta,AR学习partB
- 多目标预训练
通过多任务预训练实现能够同时处理NLU和文本生成的模型效果。
目标任务:
- 文档级别。采样一个单一的区域,其长度从原始长度的 50% 到 100% 之间的均匀分布中采样。该目标旨在进行长文本生成。
- 句子级别。限制遮盖的区域必须是完整的句子。多个区域(句子)被采样,覆盖原始文本的 15% 的词数。该目标旨在进行 seq2seq 任务,其预测结果通常是完整的句子或段落。
- 模型结构调整
1)重组了LN和残差连接的顺序;
2)使用单个线性层对输出token进行预测;
3)激活函数从ReLU换成了GeLUS。
- 微调工作
将NLU任务转换成完形填空任务,对于具体的情感分类任务,生成得到对应的结果。为了与真实标签匹配上,会将情感的类别映射到对应的不同表示。
References
- GLM: General Language Model Pretraining with Autoregressive Blank Infilling
- ChatGLM2-6B
- 清华ChatGLM底层原理详解——ChatGPT国内最强开源平替,单卡可运行
- 清华大学通用预训练模型:GLM
- 【报告笔记】 大规模语言模型系列技术:以GLM-130B为例
Ziya模型
基于LLaMA-13B训练得到的;重新构建了中文词表(LLaMA只针对英文),使得模型具备中文能力。
微调:
500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS)
评估:
重新设计了一个评估集,主要分为9类任务,32个子类共185个问题
方法
- 基于LLaMA的大规模增量训练
超参:bs:2,6m tokens,FP16混精
增量式学习110B tokens
- tokenizer
原本词表的基础上增加7k+个常见中文字,词表大小:39410,解决LLaMA原生分词对中文编码效率低下的问题。
- 数据
数据清洗-更高质量的预料。
英文数据:Books、Wikipedia、Code、OpenWebText
中文数据:“悟道”数据集(智源)+自建中文数据集
清洗操作:去重、模型打分、数据分桶、规则过滤、敏感主题过滤和数据评估
- 多阶段课程学习+增量学习
用大模型辅助划分已有的数据难度,分多个阶段进行有监督微调。
有监督微调数据包含多个高质量数据,总计500w训练样本,经过人工筛选和校验。
- 综合多种人类反馈学习算法
在以RM、PPO为主的方法基础上,结合了多种其他手段,包含人类反馈微调(HFFT)、AI反馈、基于规则的奖励系统(RBRS)和后见链微调(COHFT)弥补PPO方法的短板加速训练。
References
PaLM模型
参考
1.【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
BLOOM模型
参考
RWKV模型
参考
Chinchilla模型
References
Vicuna模型
概述:LLaMA-13B+ShareGPT用户对话数据(70k)微调
主要工作:
Vicuna在训练中将序列长度由512扩展到了2048,并且通过梯度检测和flash attention来解决内存问题;调整训练损失考虑多轮对话,并仅根据模型的输出进行微调。
效果可以:可以达到ChatGPT 90%的效果
References
Claude模型
References
数据集
BoolQ PIQA SIQA HellaSwag WinoGrande ARC-e ARC-c OBQA
MMLU
微调工具
RLHF
https://zhuanlan.zhihu.com/p/624589622
https://zhuanlan.zhihu.com/p/468828804
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat
https://huggingface.co/blog/rlhf
https://www.cnblogs.com/jiangxinyang/p/17374278.html
细节内容
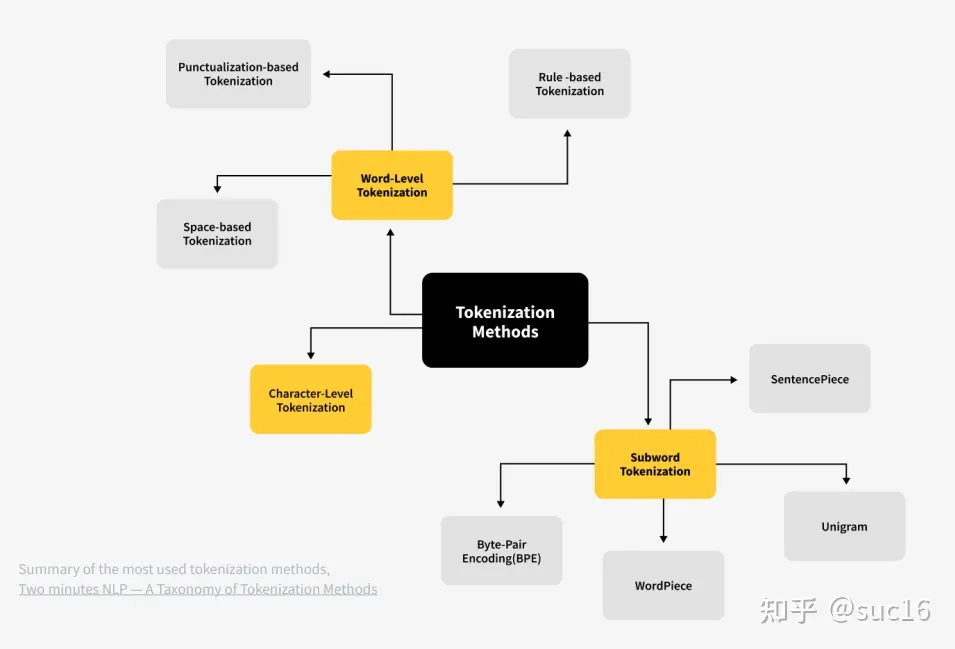
分词实现
分词粒度
word:
优点:词的边界和含义得到保留;
缺点:1)词表大,稀有词学不好;2)OOV;3)无法处理单词形态关系和词缀关系;
char:
优点:词表极小,比如26个英文字母几乎可以组合出所有词,5000多个中文常用字基本也能组合出足够的词汇;
缺点:1)无法承载丰富的语义;2)序列长度大幅增长;
subword:可以较好的平衡词表大小与语义表达能力;
分词算法
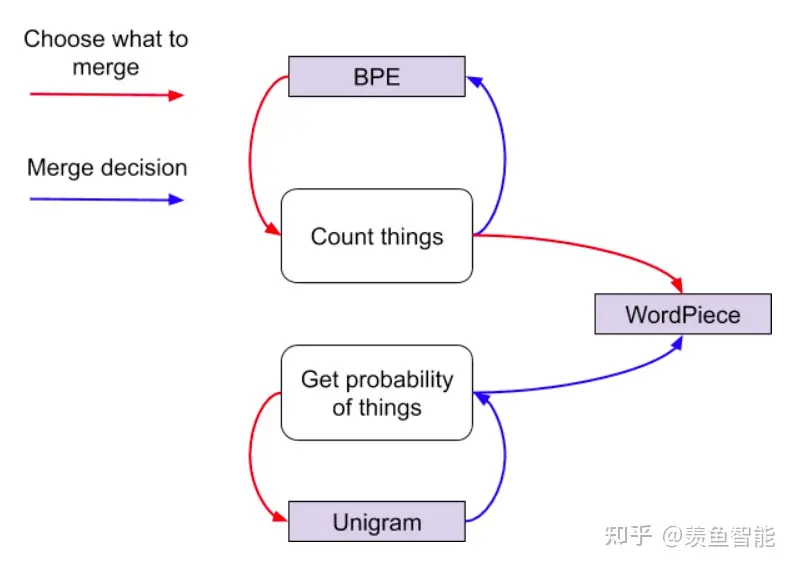
- BPE
核心思想:
从一个基础小词表开始,通过不断合并最高频的连续token对来产生新的token。
优势:
可以有效地平衡词汇表大小和编码步数(编码句子所需的token数量,与词表大小和粒度有关)。
劣势:
基于贪婪和确定的符号替换,不能提供带概率的多个分词结果(这是相对于ULM而言的);decode的时候面临歧义问题。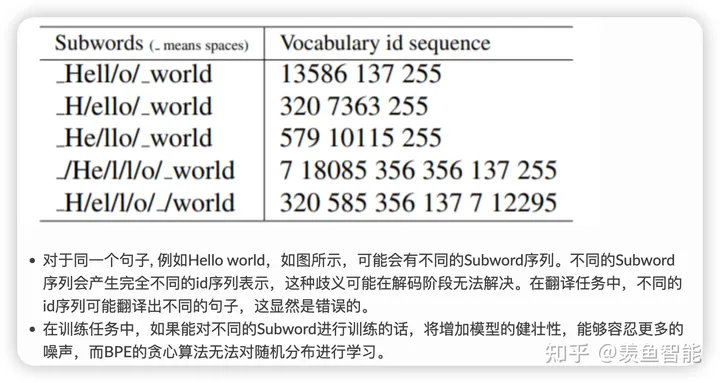
典型模型:
GPT/GPT2/RoBERTa
- Byte-level BPE
核心思想:
将BPE的思想从字符级别扩展到字节级别。(UTF-8)
由于这种方式获得的token长度会长很多,可以考虑采用可变长度的n-gram实现分割;
需要注意的:
1,ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字度节的空间。
2,UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节
3,Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节
优势:
1)效果与BPE相当,但词表大为减小;2)可以在多语言之间通过字节级别的子词实现更好的共享;3)即使字符集不重叠,也可以通过子节层面的共享来实现良好的迁移。
劣势:
1)编码序列时,长度可能会略长于BPE,计算成本更高;2)由byte解码时可能会遇到歧义,需要通过上下文信息和动态规划来进行解码。
典型模型:
GPT-2
- WordPiece
核心思想:
与BPE类似,也是从一个基础小词表出发,通过不断合并来产生最终的词表。主要的差别在于,BPE按频率来选择合并的token对,而wordpiece按token间的互信息来进行合并。注:互信息,在分词领域有时也被称为凝固度、内聚度,可以反映一个词内部的两个部分结合的紧密程度。
优势:可以较好的平衡词表大小和OOV问题;
劣势:可能会产生一些不太合理的子词或者说错误的切分;对拼写错误非常敏感;对前缀的支持不够好;
典型模型:
BERT/DistilBERT/Electra
- ULM
核心思想:
初始化一个大词表,然后通过unigram 语言模型计算删除不同subword造成的损失来代表subword的重要性,保留loss较大或者说重要性较高的subword。
优势:
1)使用的训练算法可以利用所有可能的分词结果,这是通过data sampling算法实现的;2)提出一种基于语言模型的分词算法,这种语言模型可以给多种分词结果赋予概率,从而可以学到其中的噪声;3)使用时也可以给出带概率的多个分词结果。
劣势:
1)效果与初始词表息息相关,初始的大词表要足够好,比如可以通过BPE来初始化;2)略显复杂。
典型模型:
XLNet/ALBERT/Marian/T5.
SentencePiece
SentencePiece,有些文章将其看作一种分词方法,有的地方将其视为一个分词工具包。
支持:BPE、ULM子词算法,也支持char, word分词;以unicode方式编码字符,无须Pre-tokenization;支持编码与解码的可逆;快速便捷。tokenizers库:支持快速从头训练自己的分词器