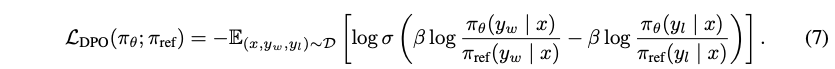LLM-RL对齐
DPO
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
核心思路:通过监督学习的方式实现RLHF对齐人类偏好的效果。
概括实现:使用奖励函数和最优策略的映射,实现约束奖励最大化问题的效果,通过单阶段策略训练优化不再需要拟合RM的训练阶段,可以直接微调对齐人类偏好
具体实现:
基于之前的RL微调的一些工作我们可以知道对应的带约束的优化问题的设置:
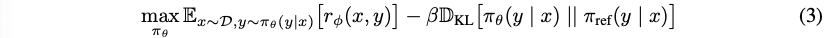
转换可以得到最优解: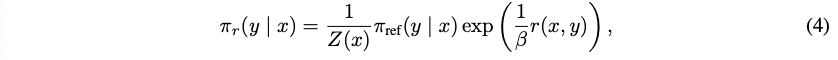
那么其对应的奖励函数可以转换成以下形式: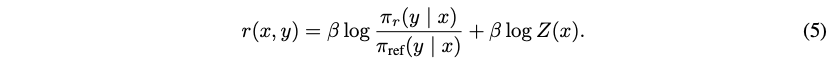
结合奖励模型的训练方式,是增大不同答案的差异性,将其引入之后,新的偏好模型可以得到是以下的形式,其中$\sigma$是sigmoid函数: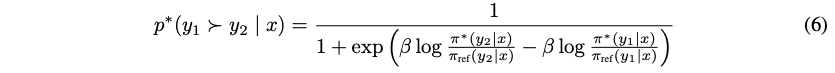
基于以上推导,即可得到DPO的目标函数,其中包含了RLHF的相关过程: