多模态模型学习
CLIP模型
Learning transferable visual models from natural language supervision
研究背景
局限:最先进的计算机视觉系统被训练来预测一组预定的物体类别。这种受限的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。
本文希望直接通过原始文本学习图像,利用了更广泛的监督来源。
主要工作
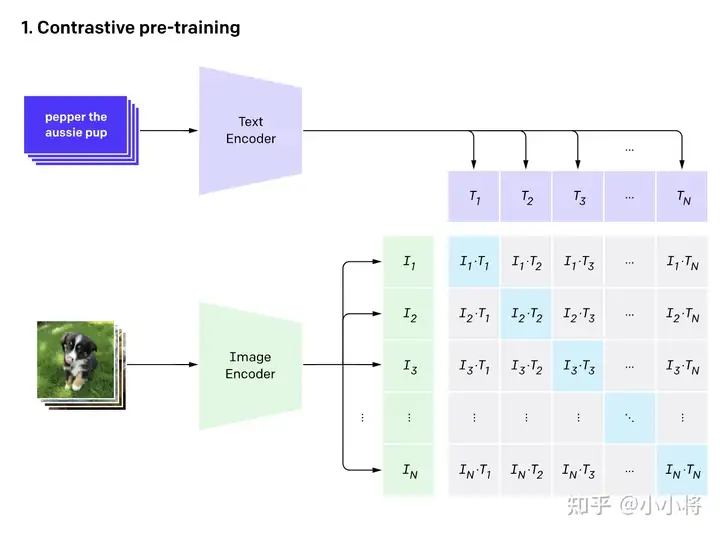
- 核心:利用text信息监督视觉任务自训练,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当;
- 高效预训练任务
- 采用双流模型获取文本(Transformer)与图像特征(ViT&ResNet)
- 多模特征投影到同一空间,计算两个模型的余弦相似度,使得匹配图文信息相似度最大,反之最小
- 采用对称交叉熵-图文的双标签;并且对图像数据进行了增强
- 大规模数据集-4亿对图像文本对
优缺点
缺点:
- 需要较大的batch-size才会有比较好的效果
References
ALBEF模型
ALBEF:Align before Fuse
研究背景
当前VLP(Vision-and-Language Pre-training)框架依旧存在着几个关系限制:
(1) 图像特征和单词嵌入都处于自己的空间中,这使得多模态编码器学习建模他们的交互更具挑战性;(双流模型)
(2) 目标检测器的标准和计算都很昂贵,因为其需要在预训练的时候人工标注bounding box,并且在推断时为高分辨率图像;
(3) 广泛被使用的image-text数据集都是从网络上收集的并且存在大类噪音,现有像$\text{MLM}$这样的预训练目标可能会过拟合噪音文本,并降低模型的泛化性能。
主要工作
模型结构
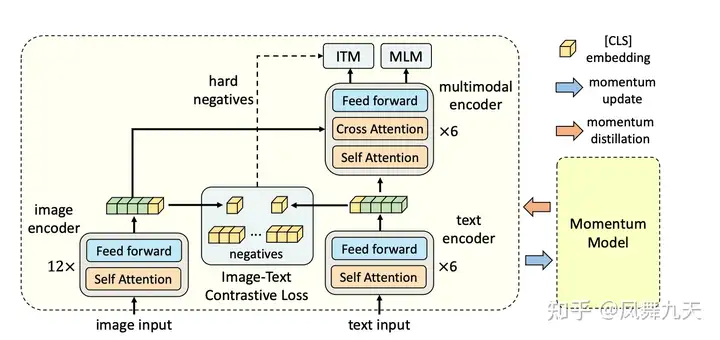
结合了单双流模型,分别由图像编码器(image encoder)、文本编码器(text encoder)和 多模态编码器(multimodal encoder)组成。其中文本编码和多模态编码分别是bert模型中的前半部分和后半部分。预训练任务
ITC-图文对比(Image-Text Contrastive Learning)
与CLIP相似,通过对图像文本特征进行余弦相似度计算,使得两个特征能够对齐。而在具体实现中,采用了memory bank+动量编码器的方式去实现,使得不用这么大的batch size也能够实现较好的效果。
MLM-掩码建模(Masked Language Modeling)
经典掩码操作,对于图像特征与文本特征均可以进行掩码操作后进行重建。
ITM-图文匹配(Image-Text Matching)
在多模编码器直接进行二分类判断图像与文本是否匹配即可。
动量蒸馏
主要用于改善在噪音监督下的学习。
具体实现:
在训练过程中,通过对模型参数进行平均来维护一个动量版本的模型,并使用动量模型来生成伪标签作为额外的监督。使用$\text{MoD}$,模型不会因为生成不同于网络标注的合理输出而受到惩罚。$\text{MoD}$不仅能够改善预训练,也能够改善下游任务。